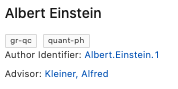
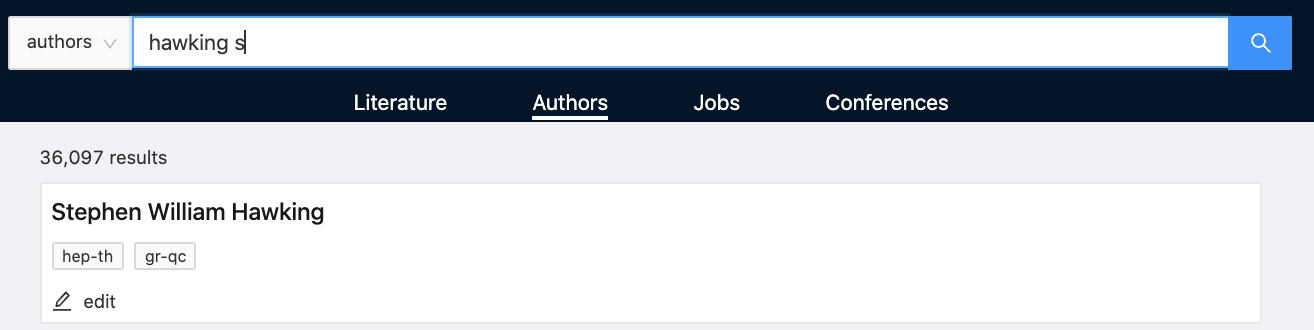
First author search is now available by typing ‘fa’ before an author name, eg. fa einstein,a
Search with texkey
A popular request from the community has been to support searches using the texkey eg: Einstein:1916vd . This is now implemented, see the example here.
Feedback
The High-Energy Physics community’s feedback has always been part of shaping and improving INSPIRE. Stay tuned for upcoming features here.
For feature requests, please fill in your feedback here. For any other request, you can contact us at <feedback@inspirehep.net>.
In response to our new work reality due to COVID-19, INSPIRE is actively looking for new ways to support researchers.
Over the past few weeks, there has been a surge of publicly available online seminars. After popular demand of listing these seminars in INSPIRE, we are working on a new seminar collection.
Users will be able to submit new seminars to INSPIRE for everyone to browse. Foreseen features include:
Linking speakers to INSPIRE author profiles
Filtering seminars by series
Direct links to attend seminars
The new INSPIRE seminars will be available in May.
If you have any other ideas on how we can better support the community in these exceptional times, feel free to contact us at <feedback@inspirehep.net>.
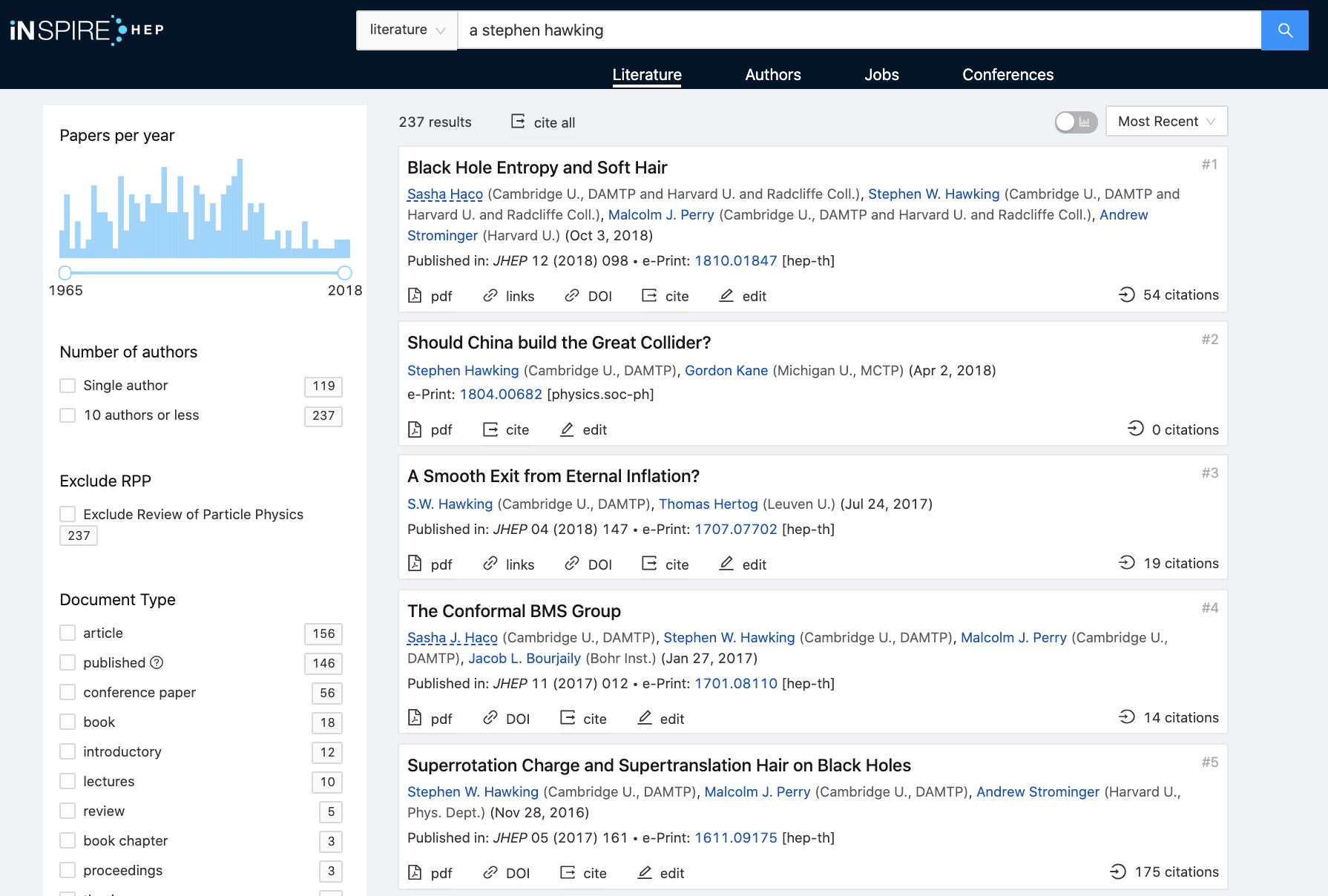
Following the new INSPIRE release and community feedback, we are pleased to announce the first of a series of improvements:
Search results display
The display of search results is improved, making it easier to read through them.
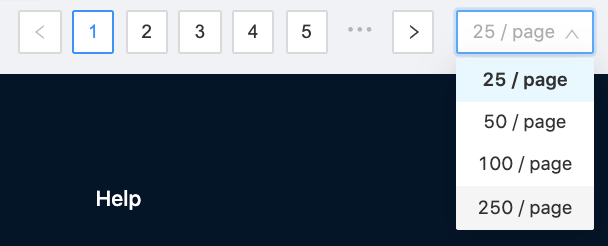
Results per page
Users are now able to select the number of results per page: 25, 50, 100 or 250. This option is available at the bottom of the search results next to the number of pages.
Improved author search
Following user reports on specific author searches, the search results have been improved in the “Authors” tab.
Other fixes
The way files and figures are handled and displayed has been improved, a reported bug in the citation summary has been fixed and all redirect links from the old INSPIRE have been corrected.
Feedback
The High-Energy Physics community’s feedback has always been part of shaping and improving INSPIRE. Stay tuned for upcoming features here. For feature requests, please fill in your feedback here. For any other request, you can contact us at <feedback@inspirehep.net>.
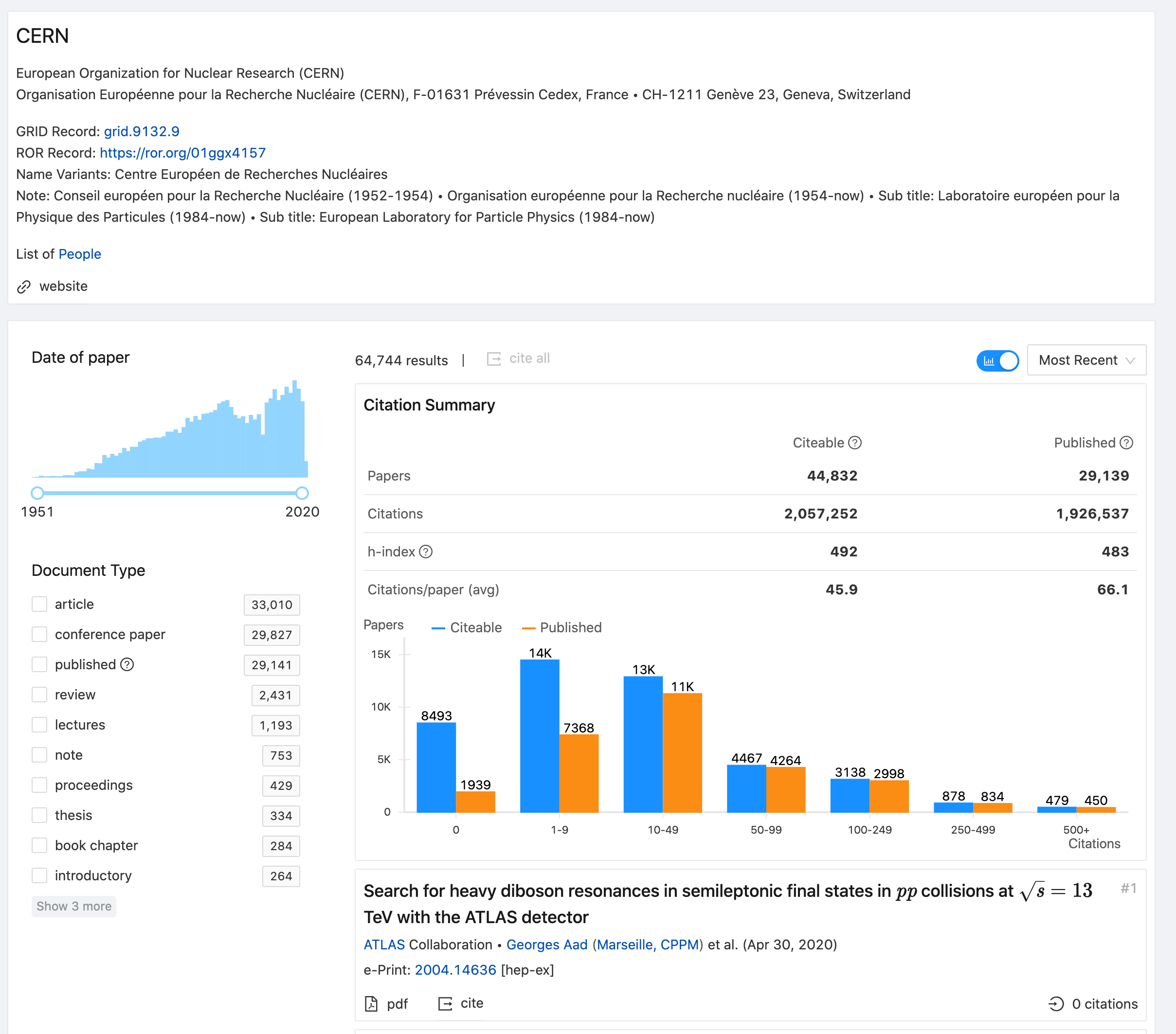
A year after releasing the INSPIRE beta version, we are delighted to announce the official release of the new, upgraded and more featureful INSPIRE. Built on top of a modern and reliable software architecture, the new INSPIRE aims at bringing the best out of the existing features while introducing new ones. Its modern, scalable and robust framework provides a solid foundation for fast and responsive services, intuitive search and comprehensive author profiles.
New features
Intuitive search, easy filtering, interactive citation summary: Take a quick tour of our new features by clicking on ‘Take the tour’ under the Help menu.
Citations differences
Citation counts may differ between the old and the new INSPIRE platforms. Learn more here.
Old INSPIRE end-of-life
The old interface will remain accessible for a limited time at https://old.inspirehep.net/ and will be switched off by June 2020. We are actively looking for community feedback to make sure the important features are implemented in the new version. For feature requests, please contact us via the form.
API and tools on INSPIRE
If you have been using the API, we’d like to hear from you! For the time being, you can still use the API by pointing explicitly to https://old.inspirehep.net/. At the same time, we are working on a new public JSON API and we are currently investigating the community needs: the information and features you would like to see in the new API, the applications you have in mind, and how these could be integrated with INSPIRE. Contact us at <feedback@inspirehep.net>.
Feedback
During this transition period, for feature requests, please fill in your feedback here. For any other request, you can contact us at <feedback@inspirehep.net>.
Redesigned to match the new INSPIRE style, this database gathers thousands of HEP conferences taking place around the globe. It enables users to refine conference search results by subject and date, but it also gives clear access to proceedings and contributions that might be linked to a particular conference. Additionally, from now on, when one submits a conference, it will be published immediately on INSPIRE.
So, let’s see how all of this looks like in more detail!
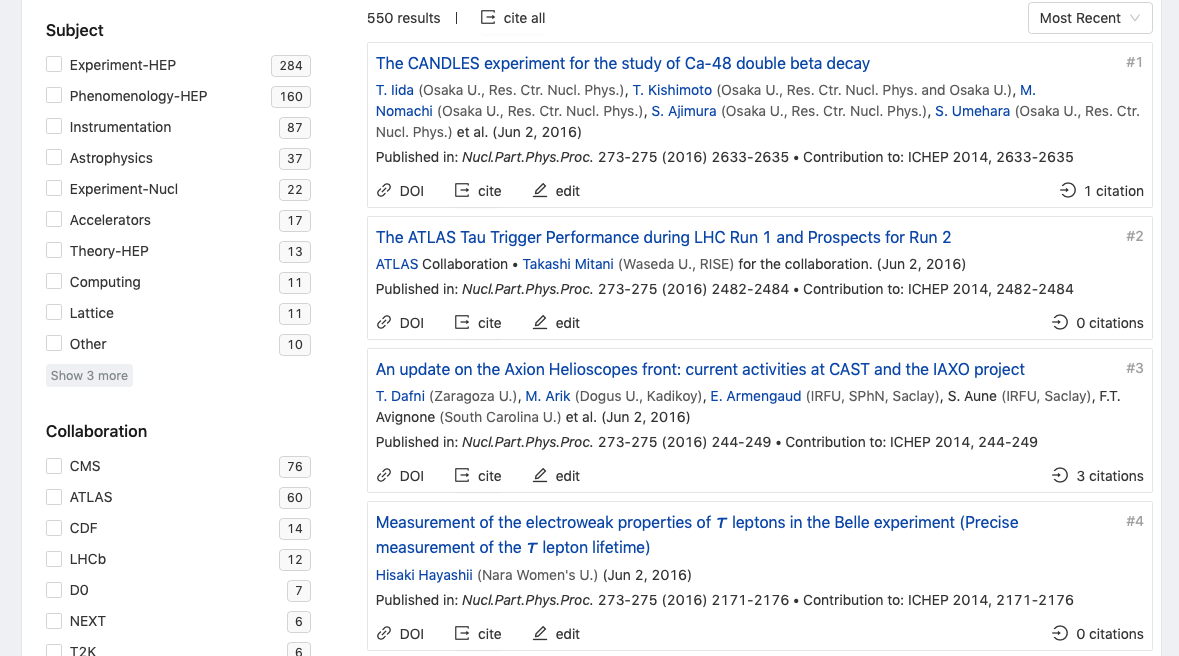
You can start searching for conferences by selecting the option via our dropdown menu straight from the homepage:
–>
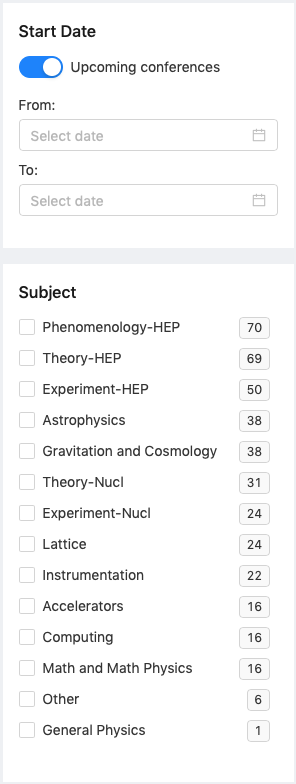
Available Search Filters: Date and Subject
Users are able to narrow down their conference search by date and subject.
As per default, the featured conferences will be the upcoming ones, so the respective button will be in blue. However, users can change this by selecting a start and, eventually, an end date from the calendar or typing a date directly in the bar, in which case, the upcoming conferences button will be switched off automatically.
Let’s perform a search to see this in practice!
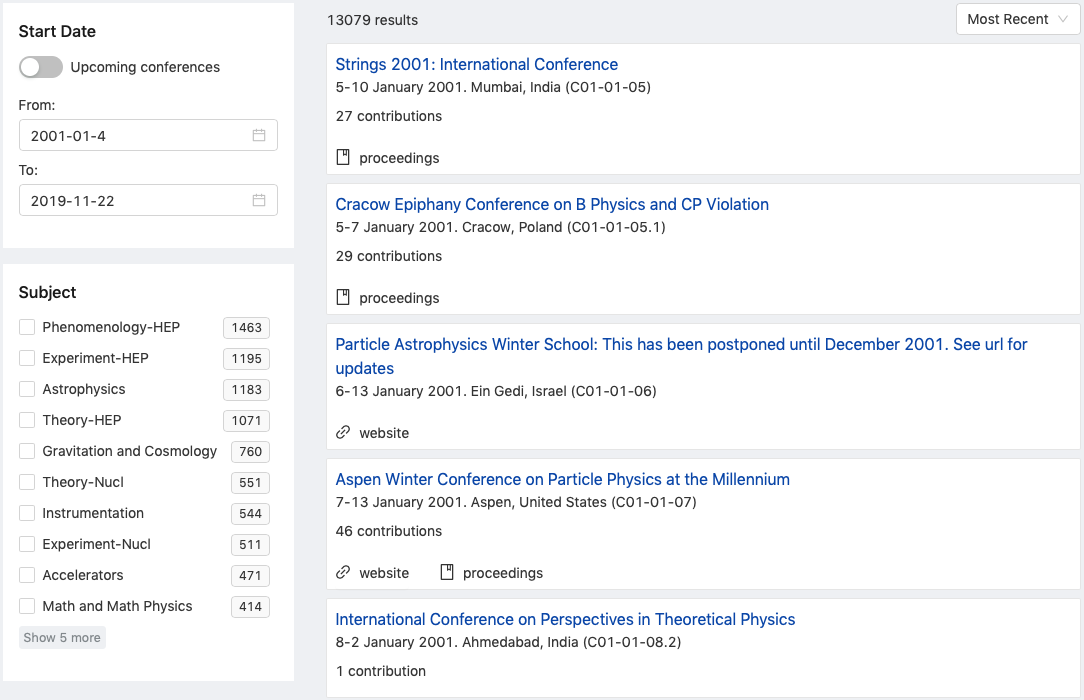
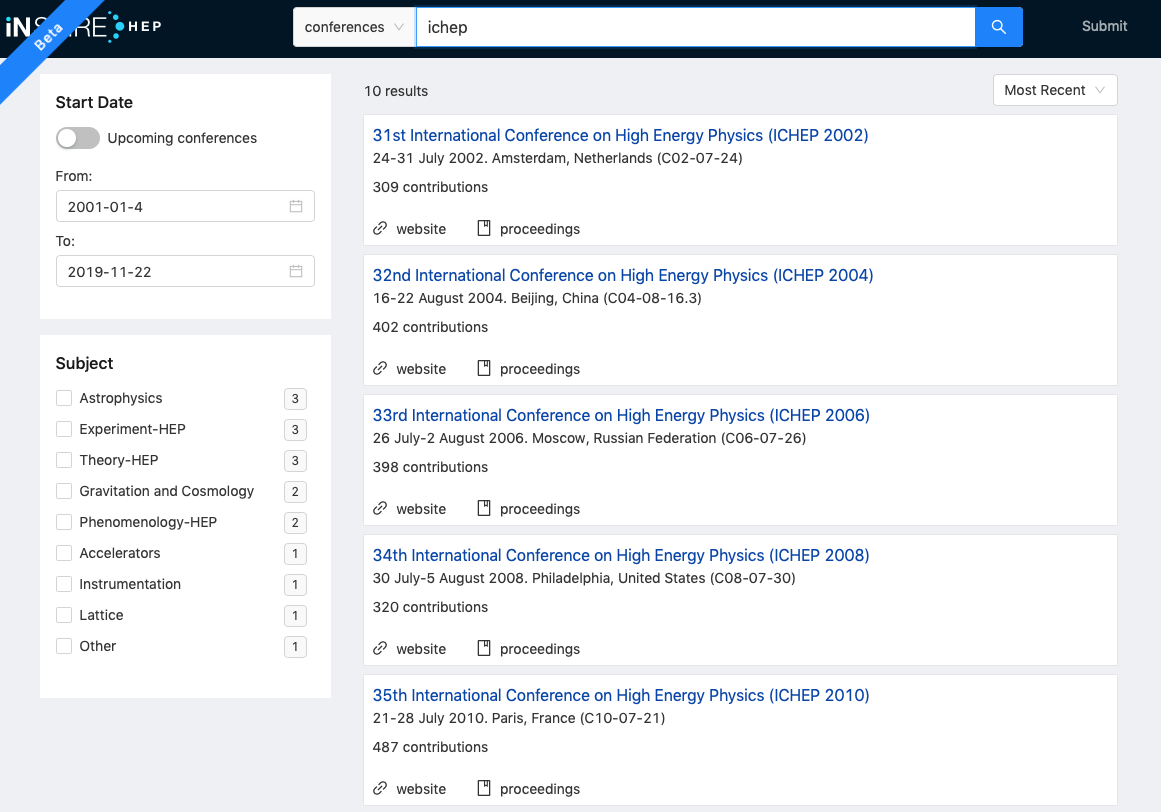
For now, we’ll only select a date, randomly:
Date selected, we hit “search”:
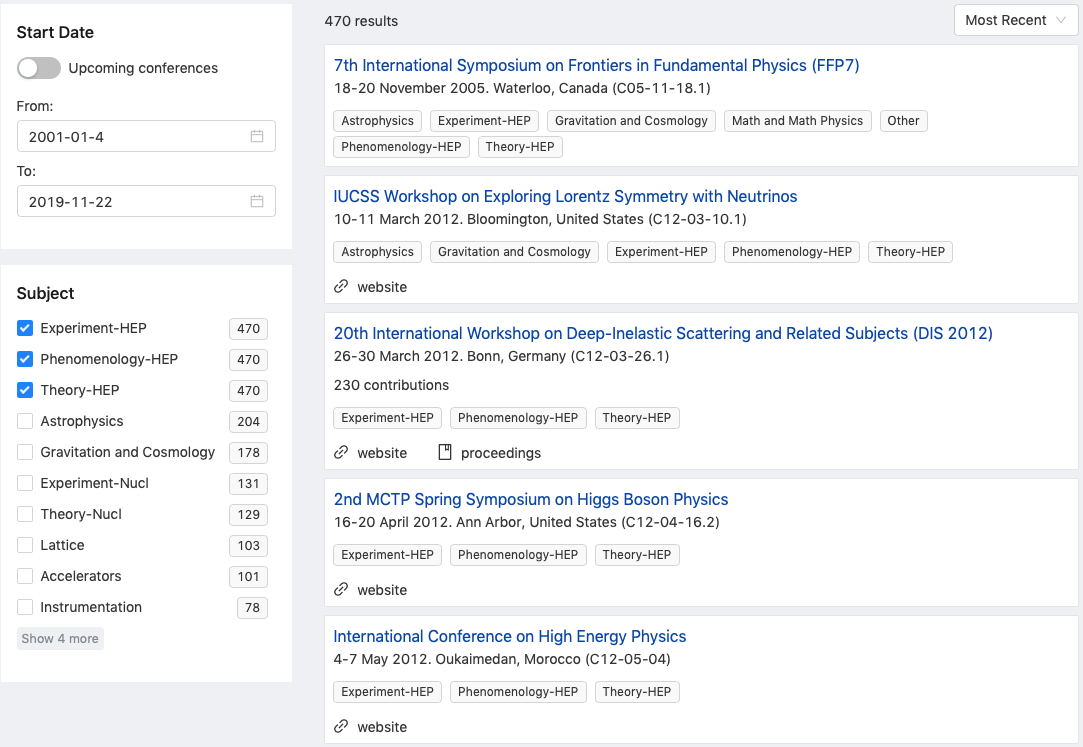
The results will always be ordered by most recent. Since we have too many, let’s now narrow them down by selecting a subject or few:
Do note that subjects filter each other out. So, the more you select, the less results you’ll see, as the search will return only those conferences that cover all the subjects you selected.
Now, if we add “ichep” as our keyword, all other things remaining the same:
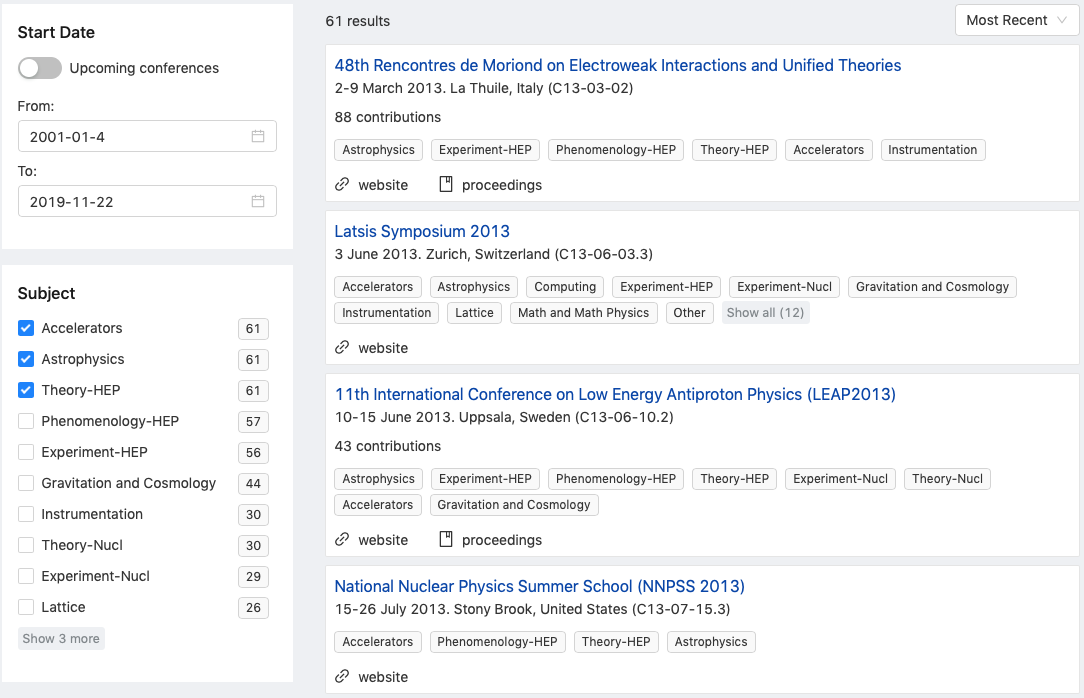
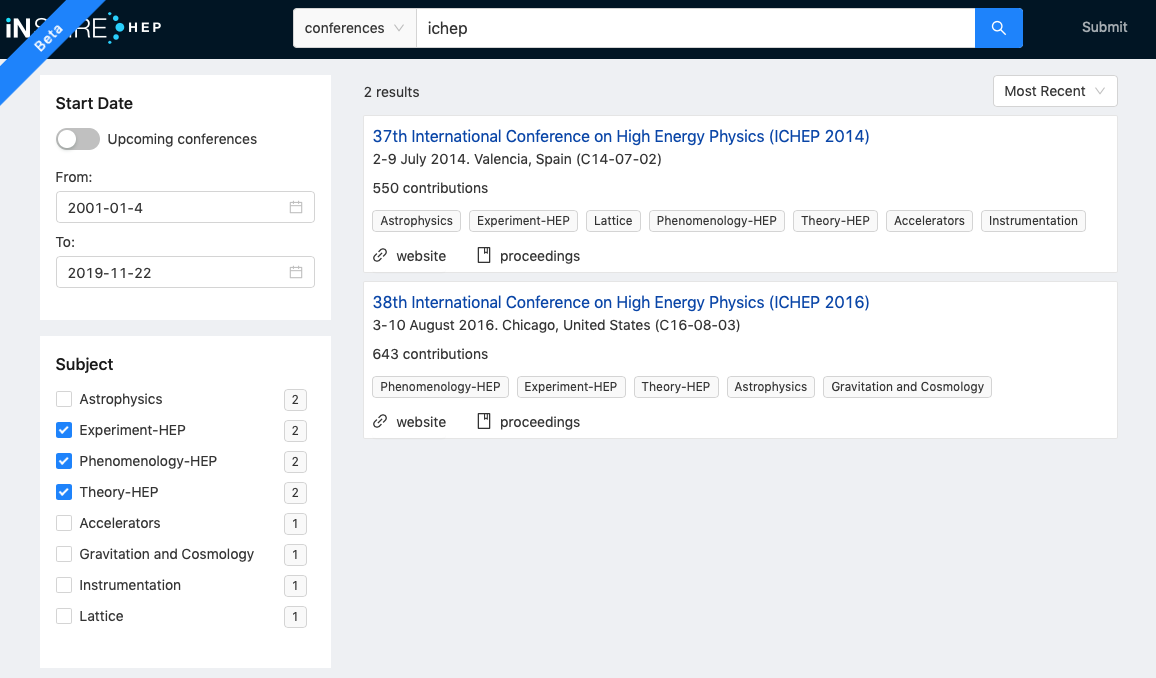
Narrowing down by subjects:
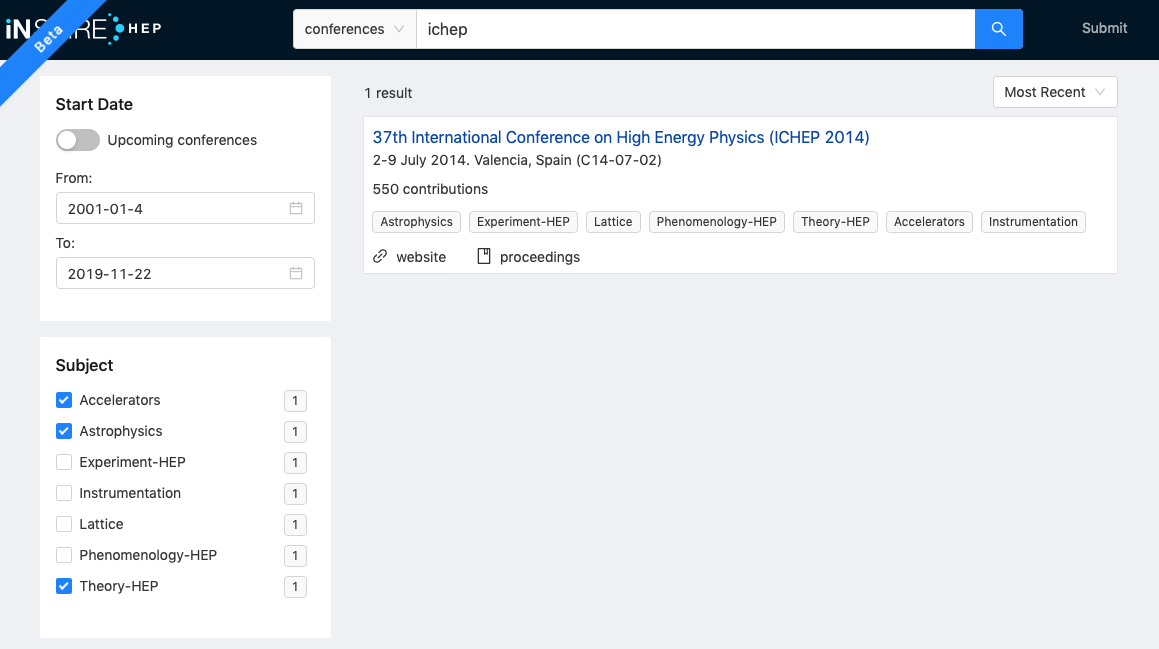
And, finally:
Conference Record Overview
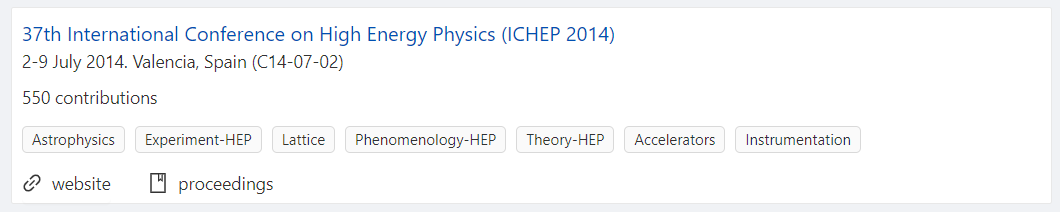
Straight from the search results page, you’ll be able to see an overview of a conference record.
For example, in the below screenshot, we can see the conference name, date, venue, website, subjects covered during the event (keywords), as well as contributions and proceedings linked to the conference:
Once you’ve clicked on a conference record, you will also be able to view which series it belongs to and its main contacts:
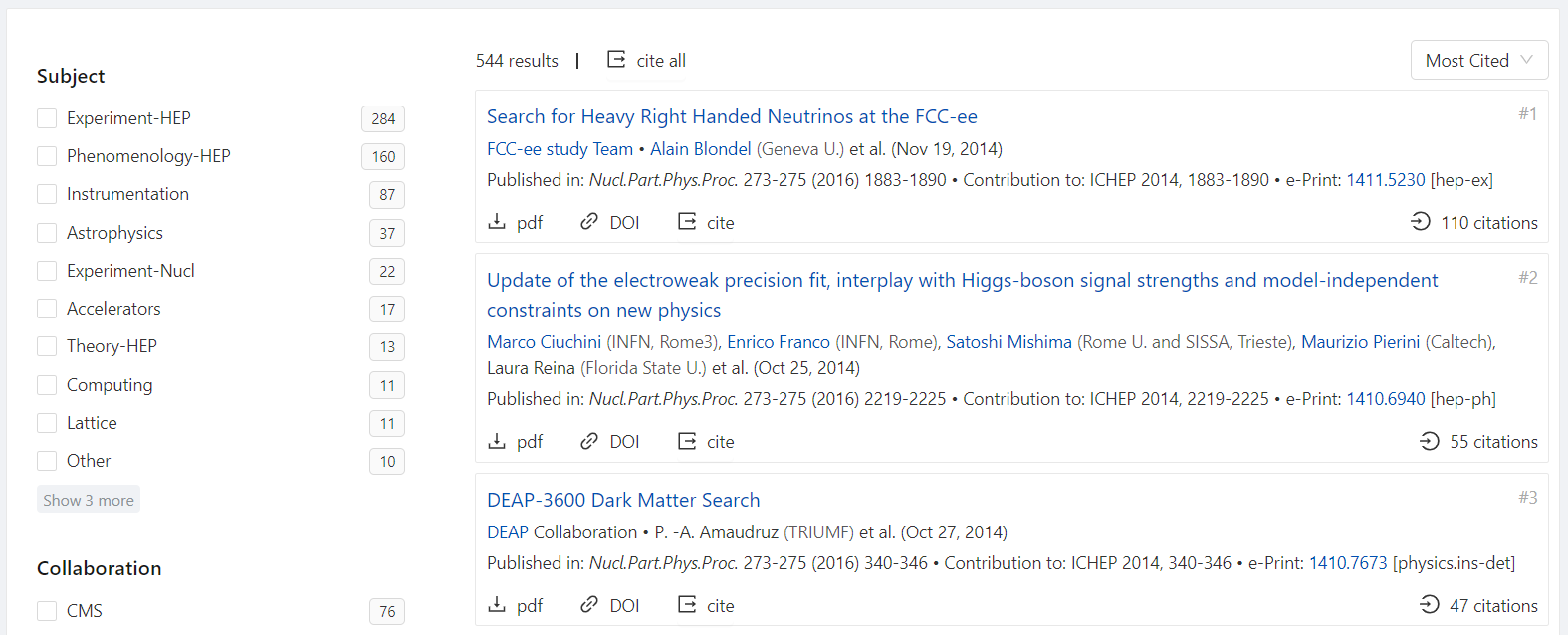
Plus, you will see the entire list of contributions to the conference, which you can further narrow down papers by subject and collaboration, and sort by most recent or cited.
Conference Submission Form
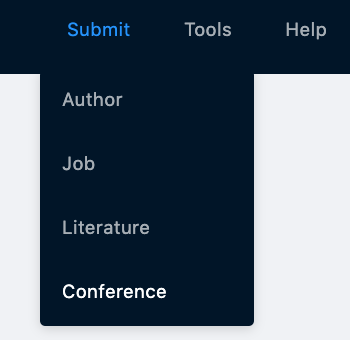
If you would like to submit a new conference to INSPIRE, you can do so by clicking on ‘Submit’ on the top right of the page:
Once you submit a conference, it will be instantly visible on INSPIRE, without the need for a curator’s approval.
——
We hope you like the new look and feel of our conference database! As always, we warmly welcome your feedback. You can email us with any comments at feedback@inspirehep.net!
In addition to being a valuable source of high-energy physics content, INSPIRE aims to build and foster a community of authors and users who will benefit from our website in more ways than one.
Step by step, we are moving towards a more user-friendly interface that will be more powerful, with a slew of new features, so both authors and other visitors can make the most of INSPIRE.
To that end, we’ve not only implemented an improved algorithm to calculate citations even more reliably, but also added additional citation information to author profile pages, which can be customized and filtered to suit specific criteria. All of these are now available on INSPIRE beta, when one consults an author page.
Now, let’s see each new feature in more detail!
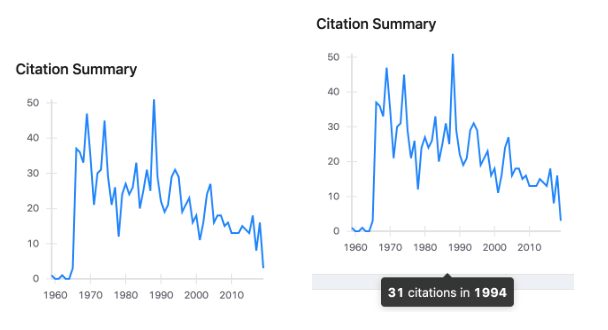
Citations per year
From now on, users will be able to view per-year citation graphs on author pages in an interactive way, as they hover over years to see how many citations an author had at a particular time.
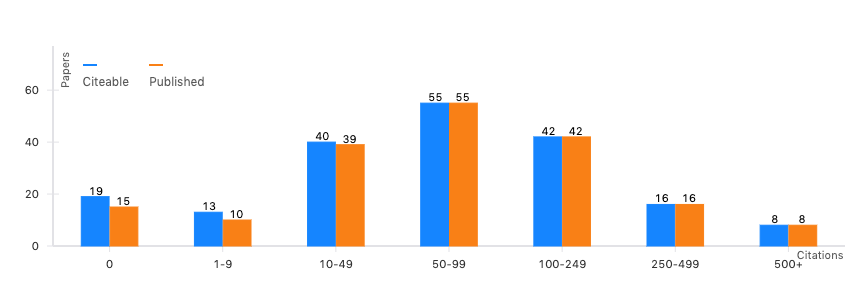
Citation Summary Graph
Our new interactive citation summary graph has been designed to facilitate paper browsing by allowing users to narrow down the options by selecting a number of filters for that purpose.
As you can see, this graph shows how many citeable and published papers an author produced.
In case you wonder, “citeable” are the papers have metadata that allow us to reliably track their citations. Published papers are believed to have undergone rigorous peer review.
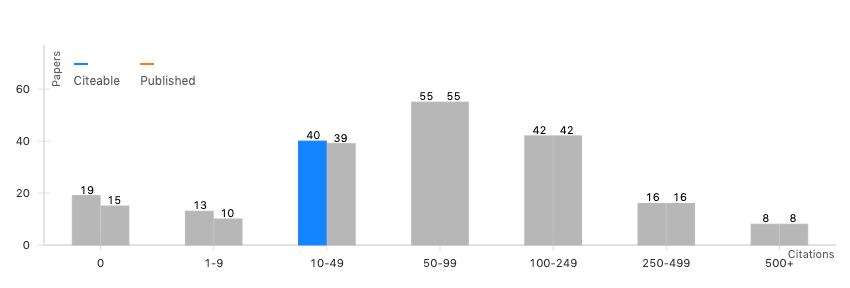
By clicking on a bar, search results are automatically updated to show papers that are part of each category:
Just below the graph, the results will be featured, with a useful filtering box on the left. This box allows further result refinement, with the option to filter by the number of authors, collaborators (co-authors), document type or collaboration. If you want to modify your search results, you will have to manually uncheck those filters you don’t want applied anymore.
Finally, you can also sort papers by most recent and most cited via a sorting dropdown menu:
—
We sincerely hope you’ll like the improvements we’ve made to author profile pages. Let us know what you think by sending us an email to feedback@inspirehep.net – any feedback is always welcome!
The INSPIRE team is glad to announce that the French National Institute of Nuclear and Particle Physics (IN2P3) has joined the INSPIRE collaboration. IN2P3 is the sixth institute to contribute to this global effort at the service of the worldwide High-Energy Physics community, alongside CERN, DESY, Fermilab, IHEP and SLAC.
IN2P3 is one of the ten institutes of the French National Centre for Scientific Research (CNRS) and represents 20 laboratories in France, 1000 permanent researchers and 1500 supporting staff, as well as 600 postdocs and PhD students. IN2P3 has already participated in INSPIRE activities since 2016, through a bilateral collaboration agreement with CERN, and a formal accession as INSPIRE partner has now been signed.
For years IN2P3 has brought enthusiastic and substantial support to open science. IN2P3 librarians (“Democrite” network) have been among the very first to massively and systematically deposit publications on the French open archive HAL (Hyper Articles en Ligne). From now on, the Democrite team is directly curating publications relevant to IN2P3 on INSPIRE, and after validation, these are automatically pushed to HAL (by SWORD protocol). Thanks to the IN2P3 open science policy and promotion, the vast majority of these records in HAL already have a direct link to an open access version, and HAL will soon be able to automatically obtain, display and archive the PDF versions of these documents. Since 2016, already 10,000 records have been treated through this process, with an average of 4,000 records per year, where half of them have IN2P3 authors and the other half have at least one French author. Thus, IN2P3 voluntarily supports the whole French physics community.
The IN2P3 team of curators brings to INSPIRE its knowledge of French affiliations and direct support of requests from French authors. They participate in the author disambiguation and publication attribution effort for French authors and can manually add content relevant to IN2P3 to INSPIRE. The very high quality of metadata in INSPIRE also allows them to extract reliable and refined metrics for the Institute. In France, they maintain a network of IN2P3 researchers to promote best practices for international visibility of their works (arXiv use, ORCID, etc.) and liaise with the other CNRS and CEA institutes interested in their contributions.
This partnership shows well that direct connections between a major international scientific information system, such as INSPIRE, and national or institutional archives are increasingly possible, facilitated by the generalization of common international identifiers (affiliations, authors, etc.) and voluntary open science policies.
We have upgraded our job submission forms, and added new features that will make it smoother for users to review and edit their job postings – all of this completely free of charge!
Up until now, if users wanted to make a modification (update a deadline, description, contact email etc.), they had to send a ticket, and our curator would make the change.
In the new system, INSPIRE beta jobs, we give more freedom to users when it comes to managing their job openings. Curators still need to approve a new job posting, but once the job is displayed, the submitter can edit the job posting, and see the changes directly online. All this is now possible because we’ve enabled users to login with their ORCID to submit and modify their job posting. Anyone can send a new job to INSPIRE, as long as they have an ORCID account. You can read more about ORCID and how to create an account here.
We’ll be running INSPIRE beta jobs in parallel with our current job platform. During this time, we’d more than appreciate your feedback (email us at feedback@inspirehep.net)! By hearing from you, our users, we’ll know what to improve in order to meet your needs in the best way possible! After a few weeks of testing, the new INSPIRE beta jobs will replace the current INSPIRE jobs platform.
Note: INSPIRE beta jobs is currently under testing; therefore it contains a selection of job postings and is not updated regularly. Any updates on INSPIRE beta jobs won’t be reflected on INSPIRE.
However, if you’re interested in proceeding with job submissions on the new INSPIRE, we hope the following instructions will be useful!
How to submit a new job posting?
Once you’ve logged in with your ORCID, you’ll be able to access the job submission form that allows you to provide information about the position you’d like to post.
To do so, click on the “Submit” button in the top right corner of our homepage, and then on “Job”:
(The job submission option will be added after testing.)
At the time of submission, a job’s status will be set to “pending” by default, until our team has reviewed and approved it. Approved jobs will appear on the list of job postings.
How to update a job posting?
As described earlier, from now on, users who have created a job posting are able to modify it, and their changes will be immediately shown in INSPIRE beta jobs.
To do so, simply go to your job posting and click the “Edit” icon at the bottom left of your job posting: . From there, you’ll access the update form, where you can change any job detail you want to.
To apply changes, you need to scroll down and click the “Submit” button: . You’ll get a message that your submission was successfully submitted if all went well.
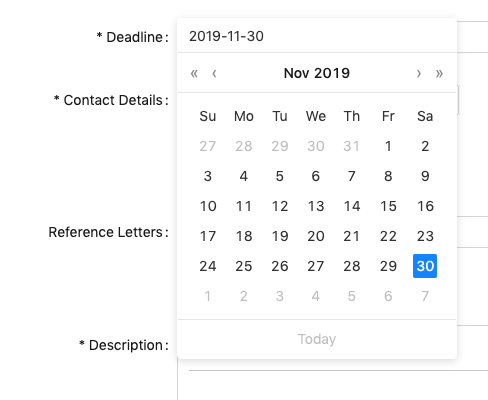
How to update a deadline?
Updating a deadline is now much simpler. On the new platform, you’ll be able to log in using your ORCID, and access the editing options directly via the job posting link you received at the time of approval.
Go to your job posting and click the “Edit” icon at the bottom left:. From there, you’ll access the update form, where you can change the deadline:
Changing the date is easily done via calendar, instead of having to follow a specific date format.
So, we get:
Once done editing, scroll down to submit via the respective button: -> and any successful submission should get the following message:
Your job posting will be instantly updated to reflect the changes you’ve made!
In our case, this would be:
How to remove a job posting?
If you, for any reason, want to remove your job posting from INSPIRE, you can do this by accessing the update form via the icon, and then simply changing the status of your job posting to “closed”:
It will immediately be removed from the job list once you’ve confirmed it by clicking on the button. You should receive the following:
If, on the other hand, you want to re-open the job, you will have to create a new job posting.
Of course, the INSPIRE team is there to help you with whatever you might need to manage your job announcements on our website. Contact us at feedback@inspirehep.netwith all your questions and feedback!
We are excited to announce INSPIRE beta, a sneak peek into the future of INSPIRE!
Built on top of a modern and reliable software architecture, INSPIRE beta aims at bringing the best out of the existing INSPIRE features while introducing new ones.
The High Energy Physics community’s feedback has always been part of shaping and improving INSPIRE; by launching INSPIRE beta to the community we enable an even closer connection, which helps us to deliver a new and better INSPIRE platform based on user needs.
That’s why INSPIRE beta is running in parallel to INSPIRE, while we work on ensuring that it will fully satisfy the needs of the HEP community. For the time being, users need to login via ORCID in order to try out INSPIRE beta, but the final platform will be available to everyone without any login required, same as the current INSPIRE platform.
You will see a powerful search, new filters (facets), and a new look-and-feel of search results and author pages.
Feel free to dive in, try out INSPIRE beta and tell us what you like and what we should improve via this feedback form.
What’s new
Search
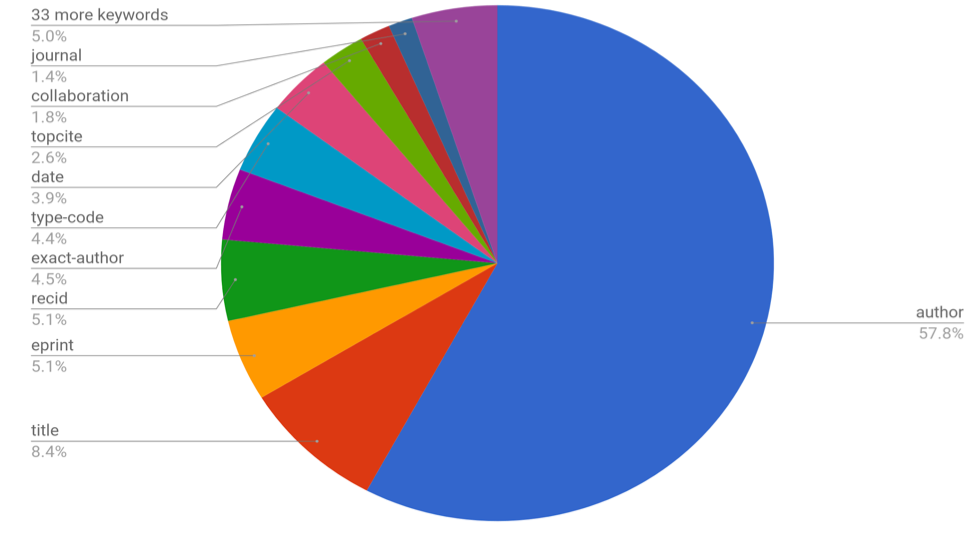
INSPIRE beta features the familiar SPIRES syntax operators, currently the most popular way of searching in INSPIRE. According to our usage data, 95% of user searches correspond to the 10 most popular SPIRES syntax operators, as illustrated here:
SPIRES syntax operators
This was a clear indication for us when deciding our search implementation priorities. In the future, we will review the implementation based on user feedback, but for now, the following SPIRES syntax operators are supported on INSPIRE beta:
In addition, we are investigating new ways to search for information using free text. We are currently improving the search results so that users can search by typing any combination of author names, title, dates etc. For example:
The new facets allow users to refine their search. You can search by date, author name, subject, arXiv category, experiment and document type. Additionally, following user requests, we added a new facet to filter out papers with more than 10 authors. The facet works similarly to the author count SPIRES operator (ac 1->10).
Citation counts
Citations are a very core function of what we do; INSPIRE aggregates content from many sources with often updated references. Currently, INSPIRE has 4 different algorithms for calculating citations, which can lead to discrepancies. In INSPIRE beta we implemented a new algorithm to calculate stable and accurate citations. So what does that mean for you? As we are still fine tuning the algorithm, you might encounter small citation differences between the two systems.
What’s next
For more info on new features and known issues, please visit our help page.
The INSPIRE service is operated by a global consortium, including IHEP in Beijing , We strive to connect the global High-Energy Physics (HEP) community, indexing over 1.000.000 relevant publications and offering accurate author profiles with citation statistics. . To celebrate our global reach, and serve the diversity of our community, some of our blog posts relevant to the Chinese HEP community will also appear in Chinese on our pages.
Let us know what you think about this and check out INSPIRE-HEP blog and twitter for more news. Our Chinese colleagues can also check our China Weibo micro-blog