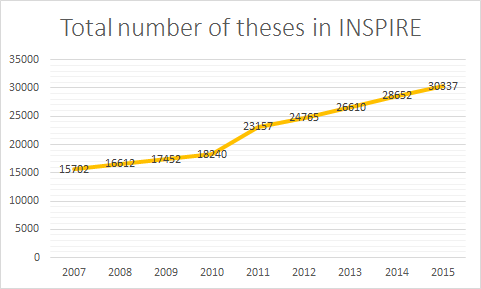
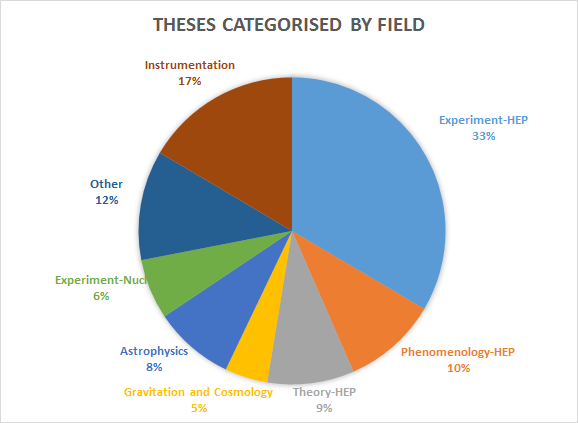
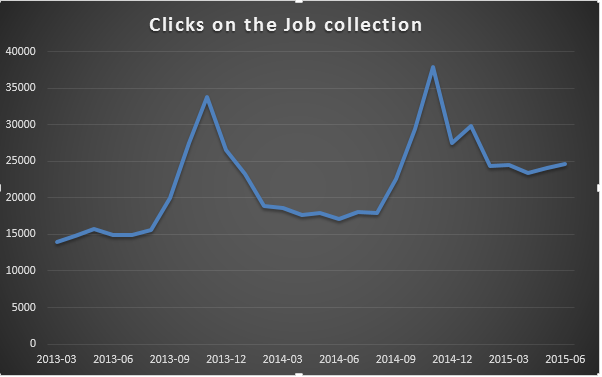
The INSPIRE Advisory Board counts eight experimental and theoretical physicists from participating laboratories and the community at large, plus the manager of INSPIRE’s sister service NASA Astrophysics Data System. The Board meets yearly, and the 2015 meeting took place at CERN on May 7. INSPIRE’s staff reviewed the team’s work during the previous year, and discussed with the Board the present challenges and the path ahead. The meeting of the Advisory Board is always a great opportunity for the INSPIRE team to reflect on last year’s achievements. After the meeting, we interviewed the chair of the advisory board, Michael E. Peskin, to hear his opinion on INSPIRE’s recent progress and its near future.
What is your impression of INSPIRE as an academic information service?
Michael E. Peskin. I have a long history with INSPIRE, I came to SLAC in 1982 and soon after that began interacting with the staff of the service. At that time it was the SPIRES information system, which I actually had used even before that. SPIRES first went online in the 1970s as a kind of terminal/command-line based service, where you hooked up on the internet, and put in some command-line statements that began with “q”, and out came a long list of bibliographic references. And this actually saved my life. In 1981. I was asked to give a review lecture at one of the big international conferences on composite models of quarks and leptons, a subject about which I knew very little. I put some queries into SPIRES, and out came reams of paper with 800 references, and I actually looked through most of them. Since then I have found it to be a very reliable service. It provides information on four high-energy physics areas (hep-th, hep-ph, hep-ex, hep-lat). It is as complete and correct as a bibliographic service can be. It is user-based so it is constantly being checked by all the users. It is multi-faceted, so it gives you direct keyword searching but also citation search. The citations are also used by people to construct stories about their careers. So that means that there is an incentive for people to very carefully check that all the links are correct and everything is provided. And actually citation searching is the most effective way of searching for any topic that you are not familiar with. The method is simple: you find a review paper, look at the papers that cite that review paper, and work your way back up the chain that presents itself. I have found this to be the most effective way of getting familiar with a scientific topic. But it requires that you have complete and detailed coverage of the field. INSPIRE has the level of coverage that is required.
What is your opinion about INSPIRE Labs?
M.P. There are some capabilities that I felt were much needed by INSPIRE. One of the strong motivations for the new framework of INSPIRE is the ability it gives for users to communicate back to the service. I think it is still true that, if you want to correct an error or add a reference, you fill a form or write an email, and then someone at INSPIRE has to parse that email, interpret it, and then take the correct action. This just wastes effort for everybody. The correct way to do this is to have a form submission that drives the user to enter information in the way that the database would like to receive it. Then it will be possible to act on user requests in just a few minutes. In that way we can build bibliographic entries, correct citations, give new citation links, and update the author pages and HEPNames data. I believe this is really the way the user input to the service really should work. And it is not only cool to provide such a service, but it is also a method that makes it much easier to maintain the integrity of the database with limited resources.
As part of INSPIRE Labs we are trying to test new features. What do you think should come next apart from the submission form?
M.P. The other part that really matters is the back end of the new framework. This gives the curators more effective tools to examine records. Eventually INSPIRE will incorporate machine learning to suggest changes in the records and, eventually, to fix things automatically. This also deserves a high priority. Besides that, everyone wants more effective searching.
How satisfied are you with INSPIRE’s operational improvements since the last 5 years?
M.P. Before the transition from SPIRES to INSPIRE, the old search engine had difficulty with the steadily increasing size and complexity of the database. Five years ago, the system was breaking down during periods of stress. Things have come a long way since then. You can still see some glitches but it is very rare that you see a serious problem.
And what about the content?
M.P. The content has increased, and this is amazing. A recent trend, aligned with the increased interest in our community in dark matter and dark energy, has been the expansion of the coverage of astrophysics. This is still an issue energetically discussed with the Advisory Board. Another trend has been the incorporation of informal public notes from the large collaborations, such as the CMS Physics Analysis Summaries. These often contain more information than the journal papers based on them and ought to be found in general INSPIRE searches. In any case, it is amazing how deep coverage of the different subjects have grown.
Which do you believe are the weakest areas of INSPIRE that should be improved?
M.P. I’ll give you two different answers: From the point of view of someone doing casual searching and trying to find a particular article or review, the size and coverage of the collection is very important. It is important to include the informal literature, as I have already noted. But, also, I use INSPIRE when I write evaluation letters for grant proposals or for appointments. I want to look everything a certain person has done,. People applying for positions or gants would like to have their personal records clear and easy to obtain. For that you need unique author identification, which is a big project. This is especially a problem for people from Asia. Recently I wrote an evaluation letter for a friend of mine born in China who has a very common last name. You cannot expect to simply put in his name and not get reams of garbage. INSPIRE gives authors the capability to claim papers and edit their profiles on their HEPnames page. He had not done that exercise, at least not recently. This led to his publications being mixed up with the publications of many other persons with that same name. The process of cleaning one’s personal record, and of identifying authors and citations has always been somewhat tedious. I hope that, with INSPIRE Labs and its new features, this problem will be reduced.
And, last question, in which direction do you see INSPIRE’s future heading towards?
M.P. I think the big question is, “Can we make machine learning algorithms sufficiently powerful that they can take over almost all of the burden from human curators?” The thing that makes INSPIRE so powerful right now, is that we start from arXiv, where authors type in the essential bibliographic information for their papers. But, still, people are human, and sometimes this information is ambiguous or incomplete, so we need to check it against other resources. Since this input is essentially imperfect, a lot of the effort must go into improving this stream of information so it can be used reliably by the academic community. There are not so many people that are willing to work as curators, but there is a lot of data in machine memory that with correct manipulation could revolutionize the way in which information is organized and managed. We are not there yet, in INSPIRE, Google, or any other service, but the situation continually improves.
INSPIRE has already brought a new way of accessing scientific resources. Today, journals are mainly used for historical data and publications. Papers from the 1980’s are still important, and they are accessed through journals. But a paper written in the past couple of years was probably issued as an eprint on arXiv. As an author, you don’t want to wait months for a journal to publish it, in order to make it public. As a reader, you want to find this in a literature search the day after it hits the internet.
But now we would like to go beyond the paper as a means of communication. I have already mentioned the fact that INSPIRE is now indexing public notes from large experimental collaborations that amplify the discussion in their papers. The next step is to provide numerical backup to these and other papers – digitizations of figures and even data sets on which the analysis is based. These data sets would not be the whole Petabyte data sets of the LHC experiments, but they could be considerably more than simple tables and lists of a few high-significance events. People who want to play with publicly released data will, more and more, be able to find it. If you write a paper based on a data set, you ought to cite the data. INSPIRE is now making it possible to index data sets directly, to provide citations for them, and to have links to the data sets appear in relevant searches.
These are two are the main directions in which INSPIRE should be reaching. High-energy physics is quite far in front of other fields when it comes to scientific information services. Being on the edge benefits us in our research, and I hope that we can stay in the front as this edge moves outward.