
Traditionally DOIs (Digital Object Identifiers) have been associated with published papers in the digital era, but papers are not the only research objects that physicists may want to search, use, and cite. We talked with Jim Simone of Fermilab about his efforts to get DOIs assigned to MILC collaboration datasets and to get records of them uploaded to INSPIRE.
How is Jim involved with the MILC collaboration?
Jim is a member of FERMILAB-LATTICE collaboration, which works closely with MILC on scientific projects involving matrix elements and flavor physics. MILC generates data sets consisting of lattice gauge configuration files, which the collaboration has made openly available for others to use, as is increasingly becoming required for federally funded research in the U.S.
What is the MILC collaboration’s connection to the International Lattice Data Grid (ILDG)?
Jim was an early organizer of the ILDG, which is intended as a data grid to enable collaborations to share gauge configurations. The ILDG metadata catalog had its limitations; it only held limited kinds of metadata, sometimes making it difficult for people to find what they were looking for. People involved with the project have been trying to fill in the gaps, including the biggest problem: connecting scientific papers produced by the data to the datasets.
Rather than reinventing the wheel, ILDG is considering to use INSPIRE as a catalog to connect papers with datasets, making the data usable and findable by all physicists, including HEP and nuclear phenomenologists, as ILDG is currently only used by lattice scientists. In INSPIRE the datasets and associated papers can be searched starting with the papers in order to see what configurations were used to get the results, though in the upcoming version of INSPIRE, the Data collection will be made public and searching will also be possible starting with the individual datasets and from there finding what papers were produced from these configurations.
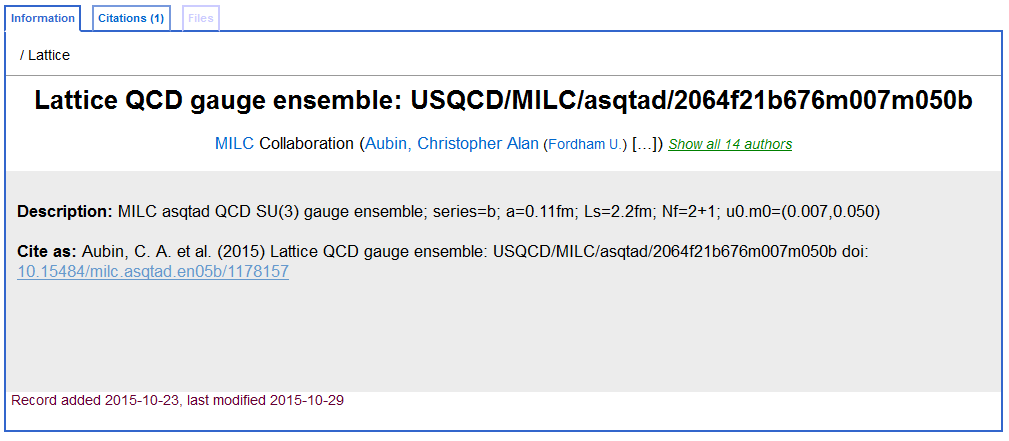 INSPIRE record of MILC dataset that has been cited. http://dx.doi.org/10.15484/milc.asqtad.en05b/1178157
INSPIRE record of MILC dataset that has been cited. http://dx.doi.org/10.15484/milc.asqtad.en05b/1178157
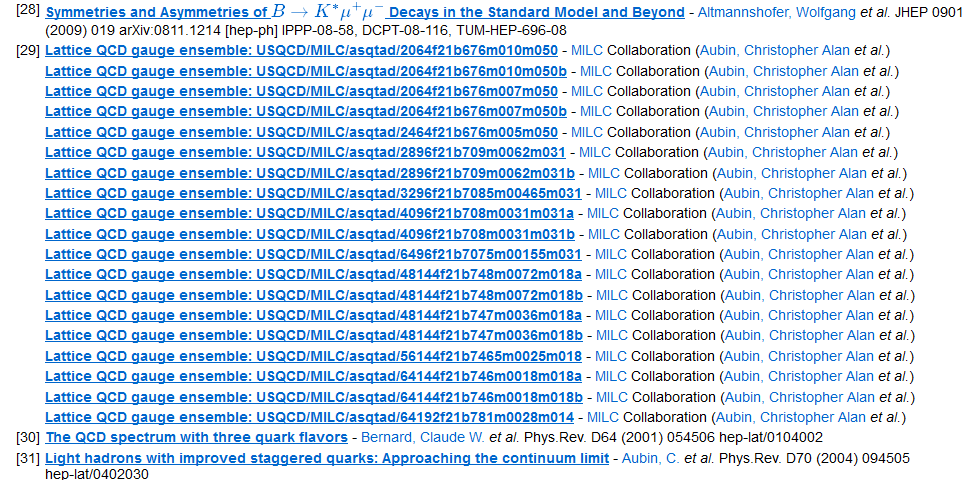 References in INSPIRE record of a paper that cited MILC datasets.
References in INSPIRE record of a paper that cited MILC datasets.
Why and how did Jim go about getting DOIs assigned to the datasets? What challenges did he face?
Jim believes DOIs, as public, persistent identifiers, are a natural mechanism to identify the datasets, which are public, first class data objects, and permanent. With DOIs, the configurations will be better integrated into the ILDG and INSPIRE.
In the case of published papers, DOIs are assigned by publishers, but this route would not work for datasets. While INSPIRE is equipped to directly issue DOIs, MILC’s direct connection to the U.S. Department of Energy (DOE) made it practical for DOIs to be issued by DOE Office of Scientific and Technical Information (OSTI). In either case, DOIs are registered with the central agency DataCite.
ILDG has started a discussion on how other groups can get DOIs for their datasets. Outside the DOE, CERN also issues DOIs, and regional ILDG groups can help members get DOIs and serve as gatekeepers to keep the metadata clean and clear. DataCite can also help researchers find registration organizations.
For Jim it was a learning experience working with OSTI and interacting with their web services. As one of his main focuses was findability, Jim wanted to include lots of searchable metadata in the dataset records so to help physicists find the particular configurations they wanted. This amount of metadata was more than OSTI was used to receiving when minting DOIs, but they were able to work with Jim’s requests and he considered them a great help through the entire process
Beyond getting the DOIs assigned, another challenge was figuring out how citations should be marked up in papers, both written and digitally. With the goals of making the datasets findable and identifiable, Jim and the ILDG wanted people to be able to see the DOI in a print version of a reference list as well as click it in a digital version. In order to make the process as transparent as possible for people citing the datasets, Jim worked with us to include instructions in the metadata of the INSPIRE records and OSTI records.
![]()
For researchers unsure of how to cite datasets that do not include specific citation guidelines in their metadata, DataCite and CrossRef have developed a DOI citation formatter that can take a DOI registered by either of these services and format its citation in a variety of styles.
When going through the publication process with a paper that used MILC configurations, Jim found the referees and copy editors weren’t familiar with how the citations should appear. Most objects with a DOI are published papers that can be cited in written format using a journal reference, volume, page range, etc., so the DOI is often left out of the text of a reference list. However, following this standard would not make the datasets adequately identifiable to the human eye.
The community known as FORCE 11 (Future of Research Communication and e-Scholarship) has developed eight principles of data citation practices with equal emphasis on human readability and machine-actionability. As these recommendations become more widely endorsed in research communities and researchers become accustomed to citing datasets in their papers, the issue of human identifiable data citations will most likely be resolved.
What advice does Jim have for others looking to make their datasets more findable and citable?
Jim has two pieces of advice: get DOIs and mark up the metadata in a way that’s sensible for the community who will use the datasets. DataCite makes this simple by being explicit about its mandatory metadata requirements, while also allowing for additional recommended and optional metadata.
At INSPIRE we look forward to integrating more dataset DOIs into our records. Send your questions and comments about dataset DOIs in INSPIRE to feedback@inspirehep.net.







