
[A guest post from our power user and advisory board member Kyle Cranmer]
We are familiar with the critical role of INSPIRE in searching for papers, following references, tracking citations, and providing author profiles. Now INSPIRE is taking steps to extend this service to data, thus creating a rich new layer to the information system of high energy physics.
Historically, papers have been the primary means for scientific communication; however, it is common to augment papers with data. The Durham HepData project has hosted this type of data for several years, and since last year, HepData is integrated with INSPIRE. Some papers have several datasets associated to it, so each dataset is given a unique, persistent Digital Object Identifier (DOI). Not only do these DOIs ensure that you can find the data, but they also provide a clear way to cite the data.
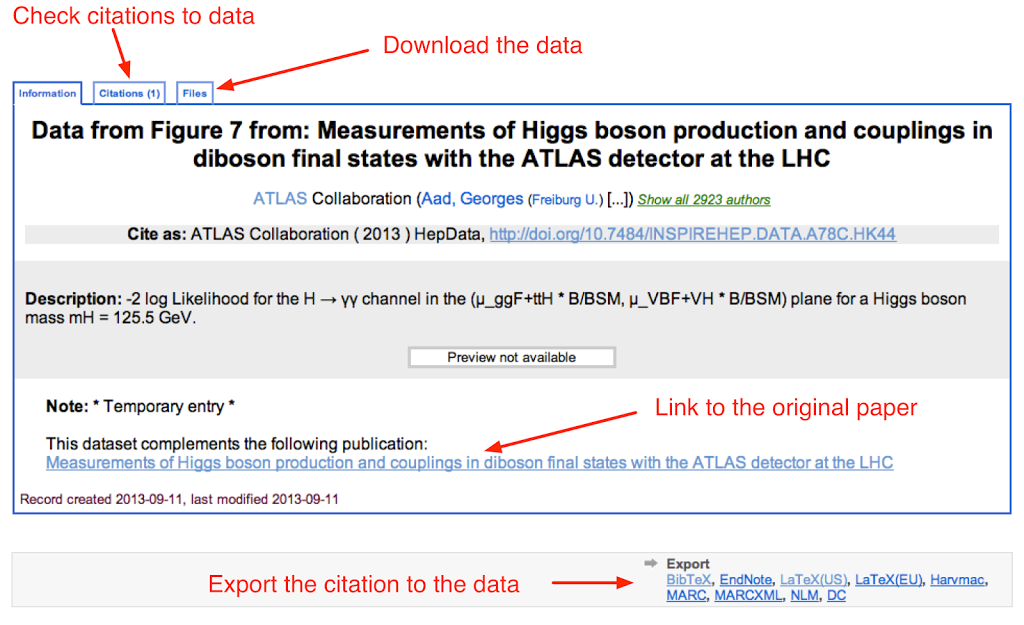
Let’s look at an example. Last month, ATLAS took an important step forward and released a digital form of the likelihood function associated to the Higgs boson property measurements. You can find these likelihood functions by clicking on the Data tab of the ATLAS paper. There are three datasets associated to this paper, and each has its own DOI. For instance, the H→γγ likelihood’s DOI is 10.7484/INSPIREHEP.DATA.A78C.HK44. If you click, the DOI will “resolve” to the INSPIRE record for this specific dataset (not the paper). From this record you can:
- download the data from the “Files” tab
- check which papers are citing this dataset from the “Citation” tab
- follow the link to the original paper
- export a properly formatted citation to the dataset itself
In addition to data coming from HepData, INSPIRE now supports data hosted in other third-party data repositories such as Figshare or The Dataverse Network. To test this out, I put some data from a phenomenological study of the CMSSM onto Dataverse — yes, theorists create data too! In this case, Dataverse issued the persistent identifier to our data since they take on the responsibility to store it. I sent the persistent identifier to INSPIRE and now it shows up in the data tab of our original paper. INSPIRE can now track citations to this data, which is hosted remotely. Nice!
The last example comes from a not-so-high-energy experiment I was involved in called APEX Jefferson Lab, which is searching for evidence of a 5th fundamental force of nature together with similar experiments such as DarkLight, HPS, and MAMI. Unlike the enormous LHC experiments, APEX had 66 collaborators that contributed to the test-run for this small, special-purpose experiment. The results of the test run were published in 2011, and this week the raw mass distribution from those 770,509 events collected by APEX was released directly on INSPIRE.
These three examples illustrate the diversity of data in HEP ranging from low-level experimental data, to theoretical predictions, to the results of statistical analysis. They also demonstrate the richness of the data layer and the need for a robust information system. Looking to the future, we can imagine an extended author profile that includes details on datasets analogous to what we are already have with papers.